|
Elliot Chane-Sane Postdoctoral Researcher in Robot Learning I am a postdoctoral researcher at LAAS-CNRS in the Gepetto team working on robot learning under the supervision of Nicolas Mansard. Previously, I completed my PhD in the Willow team of Inria Paris and École Normale Supérieure, advised by Ivan Laptev and Cordelia Schmid. I am interested in deep learning, reinforcement learning (RL), and vision, toward building generalist robots that could go everywhere and perform every task. I have worked on goal-conditioned RL, agile legged locomotion, and visual imitation from large video datasets. Prior to research, I received an engineering degree from École Polytechnique and a MASt (Part III) in Mathematical Statistics from the University of Cambridge. |

|
Research |

|
Reinforcement Learning from Wild Animal Videos
Elliot Chane-Sane, Constant Roux, Olivier Stasse, Nicolas Mansard CoRL LocoLearn Workshop, 2024 - Best Paper Award project page / video / arXiv Learning legged locomotion skills by watching thoushands of wild animal videos from the internet |

|
SoloParkour: Constrained Reinforcement Learning for Visual Locomotion from Privileged Experience
Elliot Chane-Sane*, Joseph Amigo*, Thomas Flayols, Ludovic Righetti, Nicolas Mansard CoRL, 2024 project page / video / arXiv / code End-to-end visual RL for agile legged robot parkour from depth pixels |

|
CaT: Constraints as Terminations for Legged Locomotion Reinforcement Learning
Elliot Chane-Sane*, Pierre-Alexandre Leziart*, Thomas Flayols, Olivier Stasse, Philippe Souères, Nicolas Mansard IROS, 2024 project page / video / arXiv / code A simple constrained RL method that efficiently scales to large numbers of constraints, greatly facilitating reward engineering |
|
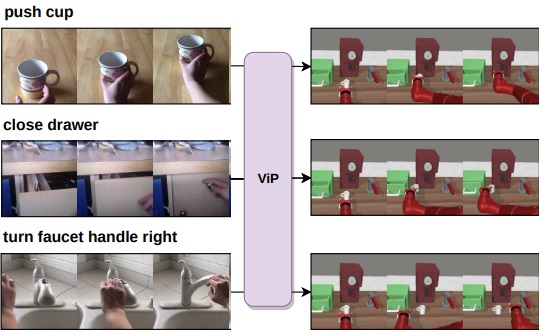
Learning Video-Conditioned Policies for Unseen Manipulation Tasks
Elliot Chane-Sane, Cordelia Schmid, Ivan Laptev ICRA, 2023 project page / arXiv Zero-shot video demonstration to robot manipulation by watching thoushands of human videos |
|
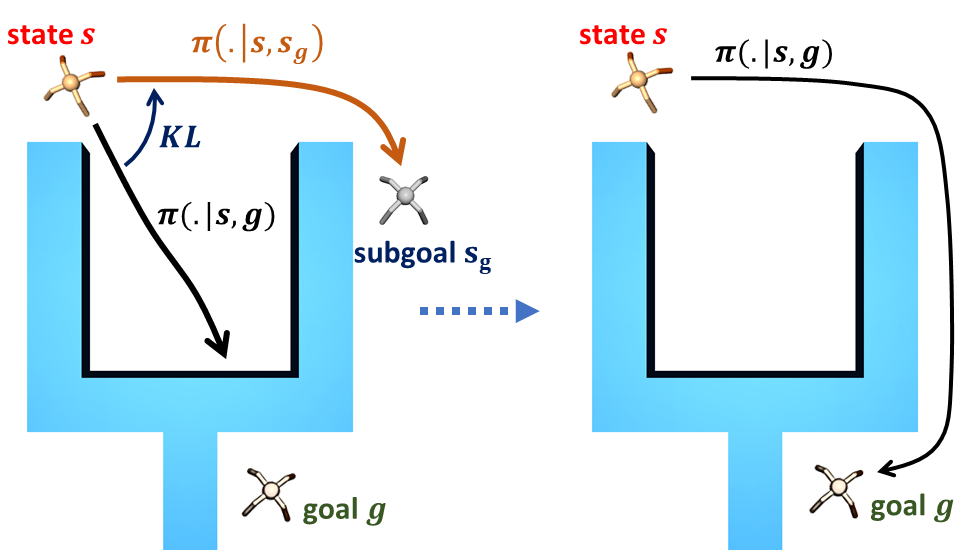
Goal-Conditioned Reinforcement Learning with Imagined Subgoals
Elliot Chane-Sane, Cordelia Schmid, Ivan Laptev ICML, 2021 project page / arXiv / code Leveraging compositionality in long-horizon reasoning to learn goal-reaching policies |
|
Design and source code from Jon Barron's website. |